概述
简答:传统 RAG 有三大痛点:切片粗暴、检索不精准、缺乏大局观。通过 Rerank 重排序、MCP 数据库联动和超长上下文模型(如 Gemini 2.0 Flash)可零代码解决。
AI 知识库并非简单的资料堆砌,传统的 RAG(检索增强生成)系统在处理复杂语境和统计任务时存在明显局限。
通过引入重排序模型(Rerank)、MCP 服务器以及超长上下文模型,用户可以在不编写代码的情况下,显著提升知识库的实用性和准确度。
相关阅读:如需 AI 编程助手,推荐阅读 Kimi k2 AI 编程实测。若需免费使用 Gemini API,可参考 边缘函数中转 Gemini API 教程。
关键评估指标
| 指标 | 说明 |
|---|---|
| 检索精度 | 系统能否从海量数据中准确找到最相关的片段 |
| 分块策略 | 如何切分长文档以保留上下文完整性 |
| 结构化数据支持 | 能否处理 Excel 或数据库中的统计类查询 |
| 上下文窗口 | 模型一次性能”读”多少内容 |
技术规格参考
下表列出了搭建高质量 RAG 知识库的推荐技术栈,均可通过 Cherry Studio 零代码配置:
| 组件 | 推荐方案 | 备注 |
|---|---|---|
| 嵌入模型 | BGE-M3 (1024维) | 免费可用 |
| 分块算法 | LangChain 递归文本分割器 | 默认约 300 字 |
| 向量数据库 | LanceDB (LibSQL) | Cherry Studio 内置 |
| 重排序模型 | SiliconFlow 免费重排序 | 二次精细化语义分析 |
| 超长上下文模型 | Gemini 2.0 Flash | 支持 100 万 Token |
RAG 技术原理
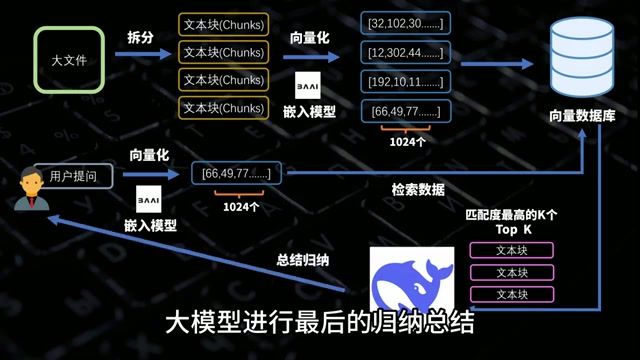
RAG 的基本流程:
- 文档切片:将长文档分割成小块
- 向量化:将文本转换为数学向量
- 相似度检索:根据问题找到最相关的片段
- 大模型归纳:将检索结果交给 AI 生成回答
RAG 的三大痛点
痛点 1:切片粗暴
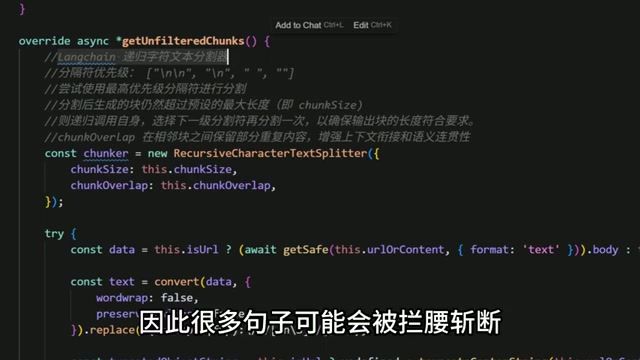
简单按字数切分会导致句子被”拦腰斩断”,AI 因丢失上下文而无法理解语义。
问题表现:
- 一个完整的句子被分到两个不同的块中
- 关键信息与其解释分离
- AI 产生幻觉或给出错误答案
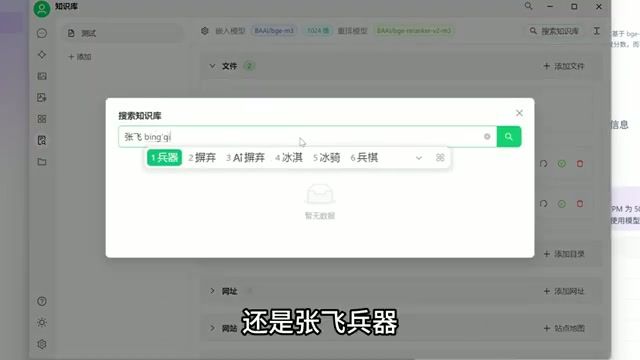
痛点 2:检索不精准
向量匹配基于纯数学运算,不代表文字实际含义。
典型案例:搜索”张飞兵器”可能匹配到包含”张”、“飞”等字的无关段落,而不是真正描述张飞武器的内容。
痛点 3:缺乏大局观
RAG 无法处理统计型问题,因为它只能看到局部碎片,无法进行全局归纳。
典型案例:问”一共多少个学生”,RAG 只能返回包含”学生”关键词的片段,无法真正统计数量。
进阶方案一:重排序模型 (Rerank)
原理:在向量检索后,使用专门的重排序模型对结果进行二次语义分析,将真正相关的内容排到前面。
效果:检索精度从 51% 提升至 70% 以上。
配置方法:
- 在 Cherry Studio 中启用 Rerank 功能
- 接入 SiliconFlow 等免费重排序服务
- 无需编写代码,GUI 操作即可完成
进阶方案二:MCP 服务器联动
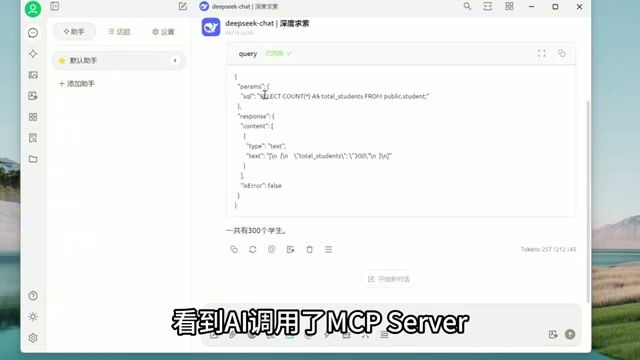
原理:通过 MCP (Model Context Protocol) 让 AI 直接操作数据库,将统计类问题转化为 SQL 查询。
效果:完美解决 Excel 统计难题,AI 可以执行精确的数据分析。
适用场景:
- 需要统计总数、平均值等聚合查询
- 处理结构化的表格数据
- 跨表关联查询
进阶方案三:超长上下文模型
原理:使用支持超长上下文的模型(如 Gemini 2.0 Flash,支持 100 万 Token),直接将整个文档喂给 AI。
实测效果:
- 成功处理 54 万 Token(整本《三国演义》)
- 能够识别出人工修改的”恶搞”细节
- 绕过了切片和检索的局限性
适用场景:
- 书籍级别的长文档分析
- 需要全局理解的复杂问题
- 对精度要求极高的场景
零代码配置流程
使用 Cherry Studio 可以实现完全零代码搭建:
- 安装 Cherry Studio:支持全桌面操作系统
- 获取 API 密钥:从 SiliconFlow 等服务商获取
- 创建知识库:通过 GUI 上传文档
- 启用 Rerank:在设置中开启重排序
- 配置 MCP(可选):连接数据库实现统计功能
方案选择建议
| 场景 | 推荐方案 |
|---|---|
| 普通文档检索 | 基础 RAG + Rerank |
| 需要统计分析 | RAG + MCP 数据库联动 |
| 超长文档分析 | 超长上下文模型直接处理 |
| 追求最高精度 | 组合使用多种方案 |
适用人群
推荐使用
- 个人知识管理者:有大量 PDF、Markdown 文档需要检索和总结
- 非技术背景职场人:希望通过零代码工具快速搭建私有助手
- 数据分析师:需要处理结构化数据的统计查询
可以跳过
- 追求绝对隐私的用户:闭源模型涉及数据出境问题
- 简单文档查阅者:偶尔翻看文档用 Ctrl+F 更高效
注意事项
- 使用 Gemini 等模型可能需要特定的网络环境
- 完全本地化的复杂 RAG 系统对硬件有一定要求
- 超长上下文模型的 Token 消耗较高,注意成本控制
总结
传统 RAG 系统的三大痛点(切片粗暴、检索不精准、缺乏大局观)可以通过以下方案解决:
- Rerank 重排序:提升检索精度
- MCP 数据库联动:解决统计能力不足
- 超长上下文模型:绕过切片限制
通过 Cherry Studio 等零代码工具,非技术用户也能轻松搭建高质量的 AI 知识库。